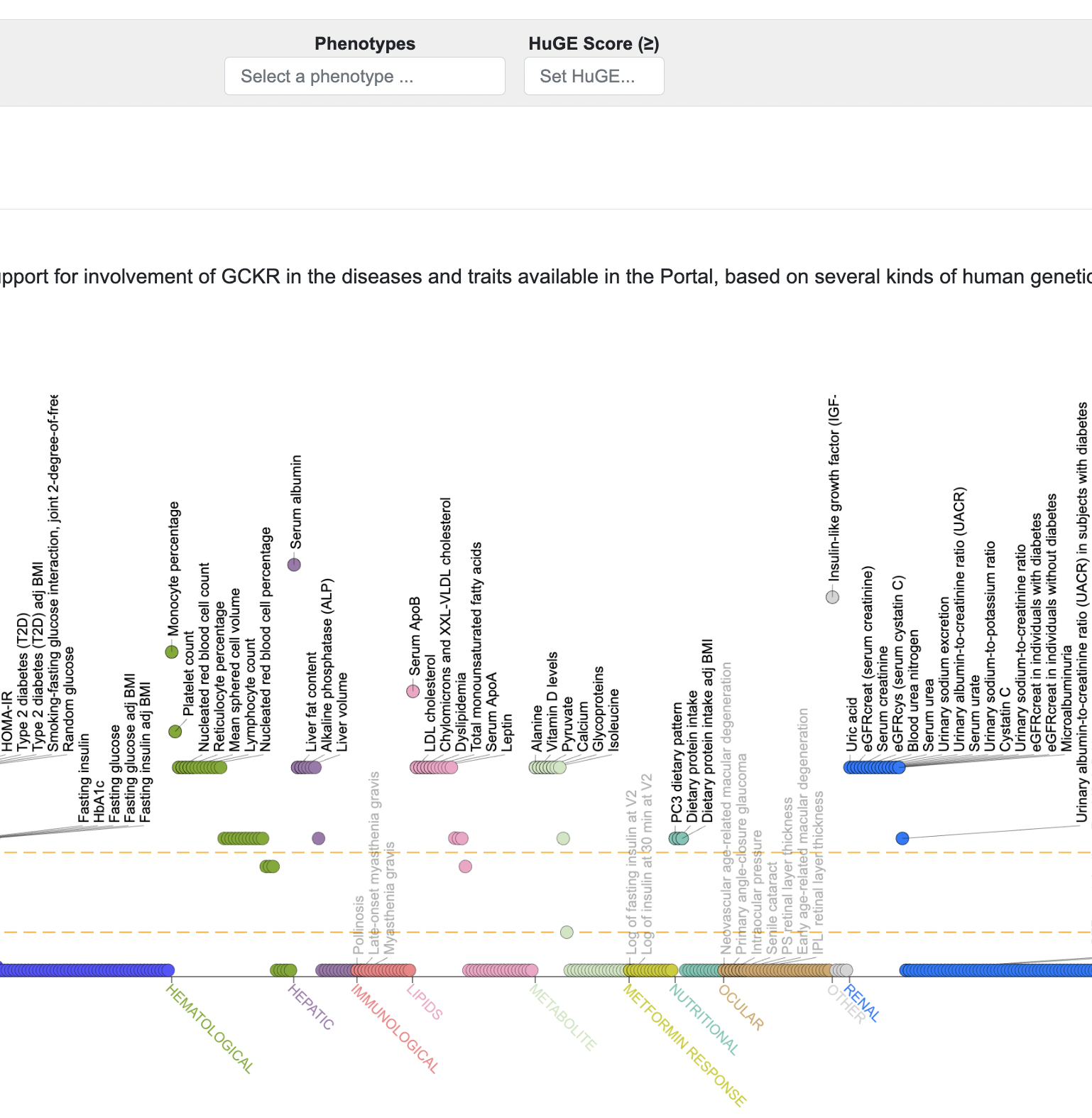
We participate in several large-scale projects that provide us with funding and research questions.

AMP-T2D-GENES
A collaboration that began among investigators funded by the NIDDK and continued in partnership with the Accelerating Medicines Partnership. It produced the largest exome sequencing dataset to date for T2D, which was the focus of our 2019 study and which we continue to analyze today. See slides from a seminar describing what AMP-T2D-GENES has taught us about rare coding variants and type 2 diabetes.